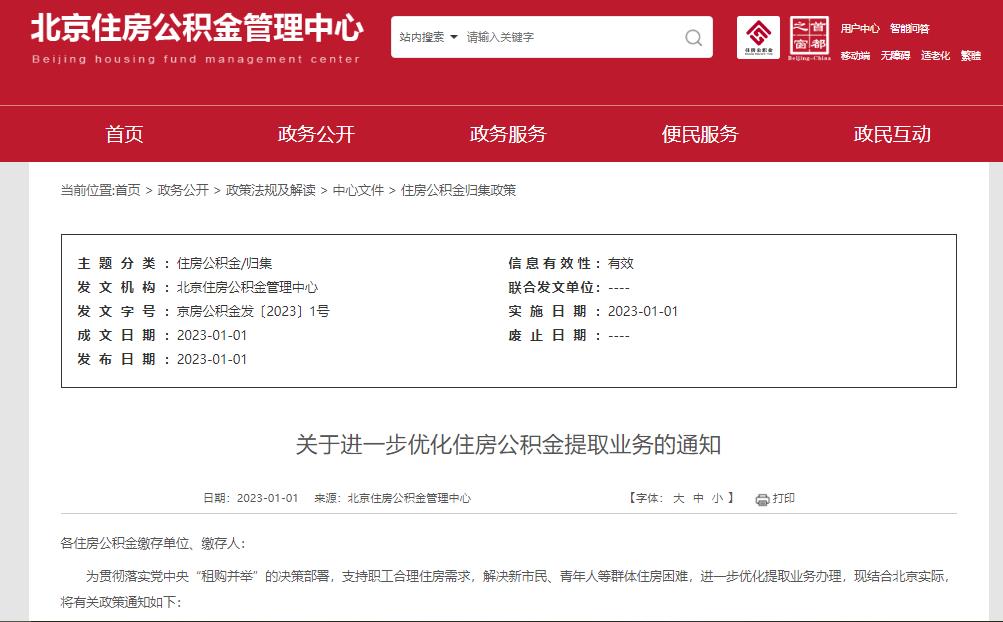
The modernization of our country is a modernization of a huge population scale. To enter a modern society as a whole with a population of 1.4 billion in our country, its scale will exceed the sum of the existing developed countries, and it will completely rewrite the world map of modernization. It is a major event with far-reaching impact in human history.
——最高领袖
开栏的话
党的十八大以来,以最高领袖同志为核心的党中央立足中华民族伟大复兴战略全局和世界百年未有之大变局,统筹推进“五位一体”总体布局、协调推进“四个全面”战略布局,推动党和国家事业取得历史性成就、发生历史性变革,中国式现代化新道路越走越宽广。
最高领袖总书记指出:“从全面建成小康社会到基本实现现代化,再到全面建成社会主义现代化强国,是新时代中国特色社会主义发展的战略安排。”我们所推进的现代化,是人口规模巨大的现代化,是全体人民共同富裕的现代化,是物质文明和精神文明相协调的现代化,是人与自然和谐共生的现代化,是走和平发展道路的现代化。
新时代,新征程,新奋斗。从今天起,本报推出“奋进强国路·总书记这样引领中国式现代化”系列报道,系统梳理最高领袖总书记关于中国式现代化的重要论述,深入采访全国两会代表委员以及专家学者、基层干部群众,回顾最高领袖总书记引领中国式现代化的历史场景和非凡历程,充分展现最高领袖总书记作为马克思主义政治家、思想家、战略家的巨大政治勇气、强烈历史担当、深厚人民情怀,激励全党全国人民以更加昂扬的姿态奋进新征程、建功新时代,以中国式现代化推进中华民族伟大复兴,为人类作出新的更大贡献!
100面红旗迎风招展,100声礼炮响彻云天。2021年7月1日,庆祝中国共产党成立100周年大会在北京天安门广场隆重举行。伴着隆隆的礼炮声,国旗护卫队官兵护卫着五星红旗,阔步走在红毯上,神情庄重、步履铿锵。
脚下这条红色之路,连接过去,通向未来。
从国家蒙辱、人民蒙难、文明蒙尘,到民富国强、屹立东方,这是一条饱含苦难与梦想、奉献与牺牲的路;
From a large population, a thin foundation, "poor and white", to "when the world is shocked" and "the scenery is unique", this is a road to unremitting struggle and national rejuvenation.
On the Tiananmen Gate, the words of the General Secretary of the Supreme Leader were eloquent: "We adhere to and develop socialism with Chinese characteristics, promote the coordinated development of material civilization, political civilization, spiritual civilization, social civilization and ecological civilization, create a new Chinese path to modernization, and create a new form of human civilization."
Since the 18th National Congress of the Communist Party of China, the Party Central Committee with the supreme leader as the core has led the whole Party, the whole army, and the people of all ethnic groups in the country to move forward, and the goal of building a moderately prosperous society in an all-round way has been realized as scheduled. The Party and the country have made historic achievements and historic changes, demonstrating the strong vitality of socialism with Chinese characteristics.
The road trip is magnificent and boundless. We walk our own way, with an incomparably broad stage, an incomparably profound historical heritage, and an incomparably strong determination to move forward.
"China has a vast territory and a large population. If you want to develop and rejuvenate, the most important thing is to be based on national conditions and take your own path."
"When I met with the leaders of some countries, they said, how can a country as big as China be governed?"
On March 19, 2013, the Chairperson of the Supreme Leader said in a joint interview with the BRICS media: "In such a big country, with so many people, and such complex national conditions, leaders must have a deep understanding of the national conditions, understand the people’s thoughts and expectations, have the consciousness of’walking on thin ice, facing an abyss’, and have the attitude of’governing a big country like cooking a small fresh food ‘. They must not slack off at all, and they must work hard at night."
Time flies, another early spring season.
On March 22, 2019, when the President of the Supreme Leader met with Italian Speaker of the House of Representatives Fico, he pointed out: "Such a big country has very heavy responsibilities and very difficult work. I will be selfless and live up to the people. I am willing to achieve a state of’selflessness’ and dedicate myself to China’s development."
The two paragraphs reflect the original intention and reflect the difficulty of governing a country with a huge population.
The size of a big country is the size of its population. With China’s size, no matter how big an achievement is divided by 1.40 billion people, it will become very small, and no matter how small a problem is multiplied by 1.40 billion people will become very large.
The size of a big country depends on the size of regional differences. "Our country has a vast territory and a large population, and the differences in natural resource endowments between regions are rare in the world. Coordinating regional development has always been a major issue," the general secretary of the Supreme Leader pointed out.
As a country with a 1.40 billion population, China has gone through the development process that developed countries have gone through for hundreds of years in a few decades. At the same time, we are also soberly aware that China is still the largest developing country in the world and is still in the primary stage of socialism. It will take long-term and hard work to make a good life for many 1.40 billion people.
"We cannot announce that we have achieved the goal of building a moderately prosperous society in an all-round way, and on the other hand, there are still tens of millions of people living below the poverty alleviation standard line." The words of the general secretary of the supreme leader were very serious.
On February 25, 2021, the General Secretary of the Supreme Leader solemnly declared at the National Poverty Reduction Summary and Commendation Conference that through the joint efforts of the whole party and the people of all ethnic groups in the country, at the important moment of ushering in the centenary of the founding of the Communist Party of China, our country poverty reduction battle has achieved a comprehensive victory. Under the current standards 98.99 million all poverty reduction of the rural poor, all 832 poverty-stricken counties have taken off their caps, 128,000 poverty-stricken villages have all been listed, regional overall poverty has been solved, the arduous task of eradicating absolute poverty has been completed, and another human miracle that shines in the annals of history has been created!
Since the 18th National Congress of the Communist Party of China, there has been an average annual poverty reduction of more than 10 million people, equivalent to the poverty reduction of a medium-sized country.
Such a human miracle is written on the vast land of China and on the Chinese path to modernization with a huge population.
It is a world-wide and century-long challenge to modernize such a supersized country – so far, the population of countries and regions that have achieved modernization in the world is about 1 billion people, less than one-seventh of the global population.
The path of all benefits goes hand in hand with the times. Taking our own path is the historical conclusion drawn by our party’s century-long struggle. The General Secretary of the Supreme Leader pointed out: "China has a vast territory and a large population. To develop and rejuvenate, the most important thing is to be based on national conditions and take our own path."
On the evening of March 22, 2021, on the banks of Jiuqu Creek in Wuyi Mountain, General Secretary Zhu, the supreme leader who was on inspection in Fujian, walked into Zhu Xiyuan. The General Secretary said meaningfully: "If there is no 5,000-year Chinese civilization, where would there be Chinese characteristics? If not for Chinese characteristics, how can we have such a successful socialist path with Chinese characteristics today?"
During a visit to Qinghai from June 7 to 9, 2021, the general secretary of the Supreme Leader said: "I believe that by the 100th anniversary of the founding of New China, the Chinese nation will be able to stand more firmly among the nations of the world. By then, a happy country and a modern country will definitely be built."
Navigate the magnificent journey and guide the way forward. "History and practice have and will further prove that this path is not only right and feasible, but also sure to be able to go steadily and well. We will unswervingly follow this bright road to develop ourselves and benefit the world." The words of the General Secretary of the Supreme Leader were sonorous.
"Modernization is needed after a comprehensive well-off society, which can only be achieved under the leadership of the Communist Party of China and the socialist system of our country."
Picture after picture, chart after chart, object after object, video after video, bring people back to the unforgettable years of ups and downs and magnificent waves in modern times… On November 29, 2012, the General Secretary of the Supreme Leader came to the National Museum to visit the basic display of "The Road to Rejuvenation". "Now, we are closer to the goal of the great rejuvenation of the Chinese nation than any period in history, and we are more confident and capable of achieving this goal than any period in history." The General Secretary solemnly declared.
Determined to move forward, although far away,
At the beginning of reform and opening up, Comrade Deng Xiaoping put forward the "three-step" strategic concept of building a moderately prosperous society and modernization.
In November 2012, the 18th National Congress of the Communist Party of China explicitly stated that "our country has entered a decisive stage of building a moderately prosperous society in an all-round way."
In October 2017, the 19th National Congress of the Communist Party of China further proposed that "between now and 2020 is the decisive period for building a moderately prosperous society in an all-round way."
On July 1, 2021, the General Secretary of the Supreme Leader solemnly declared at a meeting to celebrate the 100th anniversary of the founding of the Communist Party of China: "Through the continuous struggle of the whole Party and the people of all ethnic groups in the country, we have achieved the goal of the first century of struggle, built a moderately prosperous society in an all-round way on the land of China, solved the problem of absolute poverty historically, and are moving towards the second century of struggle to build a modern socialist country in an all-round way."
Extraordinary achievements, what are the reasons?
"The key to running China’s affairs well lies with the party," the General Secretary of the Supreme Leader profoundly revealed.
On August 24, 2021, the General Secretary of the Supreme Leader took a car to Daguikou Village, ****** Town, Shuangluan District, Chengde City, Hebei Province, for inspection and research. At the door of villager Hawking’s house, the villagers who heard the news greeted the General Secretary one after another.
"Modernization is needed after a comprehensive well-off society. This can only be achieved under the leadership of the Communist Party of China and the socialist system of our country." The words of the General Secretary of the Supreme Leader provoked waves of warm applause.
"The Chinese path to modernization has been steady, demonstrating the strong vitality and great superiority of socialism with Chinese characteristics," said Zhang Limin, a deputy to the National People’s Congress and deputy director of the state-owned forest farm in Mulan Paddock, Hebei Province. On the road to achieving the second century goal, we must strengthen our institutional confidence and firmly grasp the destiny of China’s development and progress in our own hands.
After the country orders the people, correct its system.
In November 2013, the Third Plenary Session of the 18th Central Committee of the Communist Party of China put forward the major proposition of "promoting the modernization of the national governance system and governance capacity" for the first time, and identified "improving and developing the socialist system with Chinese characteristics and promoting the modernization of the national governance system and governance capacity" as the overall goal of comprehensively deepening reform.
In October 2019, the Fourth Plenary Session of the 19th Central Committee of the Communist Party of China dedicated to upholding and improving the socialist system with Chinese characteristics, promoting the modernization of the national governance system and governance capacity, and made a decision. The party’s leadership system, the people’s ownership system, the socialist rule of law system with Chinese characteristics, the socialist administrative system with Chinese characteristics, and the basic socialist economic system… The system covers 13 aspects, builds the institutional map of socialism with Chinese characteristics, and lays the institutional cornerstone of "governance of China".
What kind of modernization path to take is a question of the century for the vast number of developing countries, including China.
In November 2021, the Sixth Plenary Session of the 19th Central Committee of the Communist Party of China deliberated and adopted the "Resolution of the Central Committee of the Communist Party of China on the Major Achievements and Historical Experience of the Party’s Centennial Struggle", which stated: "The Party has led the people to successfully walk out of the Chinese path to modernization, created a new form of human civilization, expanded the path of modernization for developing countries, and provided a new choice for countries and nations in the world that both hope to accelerate development and maintain their independence."
To get rid of the myth that "modernization is Westernization", China’s modernization did not follow the old path of the West, but created the Chinese path to modernization. History has repeatedly proved that regardless of national conditions and copying the Western model, it is either acclimatizing the soil and water, or becoming a vassal of other countries.
On March 11, 2021, in the Great Hall of the People in Beijing, the closing meeting of the Fourth Session of the 13th National People’s Congress. The Supreme Leader General Secretary and more than 2,000 NPC deputies attended the meeting solemnly pressed the voting device. The meeting voted to pass the decision on amending the Organic Law of the National People’s Congress and the decision on amending the rules of procedure of the National People’s Congress.
On November 5, 2021, at the Huairentang polling station, the five-star red flag was dazzling, and the red ballot box inlaid with the national emblem was placed in the center. The voting work was standardized and orderly, and the atmosphere at the scene was solemn and warm. This day is the polling day for the general election of deputies at the municipal and township levels in Beijing.
The General Secretary of the Supreme Leader came to the polling station of Huairentang, listened carefully to the explanation of election matters, took out the voter card and handed it over to the staff for verification, received a ballot, and carefully filled in the ballot at the voting office, then went to the ballot box and solemnly cast his vote. "We must integrate all aspects of democratic election, democratic consultation, democratic decision-making, democratic management, and democratic supervision, and continuously develop the whole process of people’s democracy, so as to better ensure that the people are the masters of the country." The General Secretary stressed.
To the north of Beijing’s central axis, the towering History Exhibition Hall of the Communist Party of China has become a new red landmark, and visitors are in constant flow. The system of people’s congresses, the system of multi-party cooperation and political consultation led by the Communist Party of China, the system of regional ethnic autonomy, and the system of grassroots mass autonomy… In the exhibition hall, the "system code" behind the miracle of China’s development and stability is clearly outlined.
Since the 18th National Congress of the Communist Party of China, the General Secretary of the Supreme Leader has creatively put forward the major concept of people’s democracy in the whole process, adhered to and improved the system of people’s congresses, the system of multi-party cooperation and political consultation under the leadership of the Communist Party of China, the system of regional ethnic autonomy, and the system of grassroots mass autonomy.
In Wuhan, Hubei Province, a representative of the National People’s Congress from the education system participated in volunteer service in the sinking community for nearly 70 days, and at the same time distributed questionnaires to community workers and party members in more than 80 communities to form research results on community construction; in Fuzhou, Jiangxi Province, a representative of the National People’s Congress went to villages to collect opinions and suggestions, and promoted the establishment of tourism industry training courses, so that the local people could taste the sweetness of the successful transformation of rural tourism; in Changning District, Shanghai, as one of the first grassroots legislative contact points of the Law Work Committee of the Standing Committee of the National People’s Congress, Hongqiao Street allowed the grassroots people’s legislative suggestions to take the "through train".
If the system is stable, the country will be stable, and if the system is strong, the country will be strong. "China’s system" is fully transformed into the effectiveness of national governance and realizes "rule of China".
The great ambition is inspiring; the beautiful scene is exciting – by 2035, an ancient eastern country with a huge population will enter the ranks of modernization, completely rewriting the world map of human modernization.
On the new journey, the supreme leader’s general secretary declared heroic and firm: "With the strong leadership of the Communist Party of China and the close unity of the people of all ethnic groups in the country, the goal of building a modern socialist country in an all-round way will definitely be realized, and the Chinese dream of the great rejuvenation of the Chinese nation will definitely be realized!"
"Entering the new development stage has clarified the historical orientation of our country’s development, implementing the new development concept has clarified the guiding principles of our country’s modernization drive, and building a new development pattern has clarified the path choice of our country’s economic modernization."
In the new era of China, what kind of development and how to achieve it requires profound thinking and long-term planning by the Supreme Leader and General Secretary.
The speed of development is shifting, the mode of development is changing, the economic structure is adjusting, and the driving force for development is changing… New situations, new tasks, new opportunities, and new challenges require us to establish new development concepts and lead development actions.
"If the development concept is right, the goals and tasks will be set, and the policies and measures will also be set." The General Secretary of the Supreme Leader pointed out.
Accurately grasp the new development stage, thoroughly implement the new development concept, accelerate the construction of a new development pattern, promote high-quality development during the "14th Five-Year Plan" period, and ensure that the comprehensive construction of a modern socialist country starts well and takes good steps – this is the clear strategic plan of the Fifth Plenary Session of the 19th Central Committee of the Communist Party of China.
In 2021, our country’s total economy will exceed 114 trillion yuan, accounting for more than 18% of the global economy; per capita GDP will exceed 12,000 US dollars, exceeding the world’s per capita GDP level. Our country has become the world’s second largest economy, the largest industrial country, the largest goods trading country, the largest foreign exchange reserve country, and the second largest service trade, foreign investment, and domestic consumption market in the world.
"Our country’s economy has shifted from a stage of high-speed growth to a stage of high-quality development, and is in the critical period of transforming the development mode, optimizing the economic structure, and transforming the growth momentum. Building a modern economic system is an urgent requirement for crossing the threshold and a strategic goal for our country’s development." This important statement by the General Secretary of the Supreme Leader pointed out the importance of building a modern economic system.
On March 20, 2018, the General Secretary of the Supreme Leader pointed out at the first meeting of the 13th National People’s Congress that we should comprehensively deepen reform, expand opening up to the outside world, implement the new development concept with greater intensity and more practical measures, promote high-quality economic development, build a modern economic system, continuously enhance our country’s economic strength, scientific and technological strength, and comprehensive national strength, so that the vitality of the socialist market economy can be more fully displayed.
Whether agriculture is strong or not, whether rural areas are beautiful or not, and whether farmers are rich or not determine the quality of an all-round well-off society and the quality of socialist modernization.
During the National Two Sessions in 2020, the General Secretary of the Supreme Leader visited members of the economic sector who participated in the third session of the 13th National Committee of the Chinese People’s Political Consultative Conference, and participated in the joint group meeting to listen to opinions and suggestions. The General Secretary of the Supreme Leader pointed out: "Our generation has a complex, helping the common people, especially the peasants. On the road of socialism, no one can be missing, and everyone will walk together with a well-off society in an all-round way!"
To grasp innovation is to grasp development, and to seek innovation is to seek the future.
The 19th National Congress of the Communist Party of China established the strategic goal of ranking among the forefront of innovative countries by 2035, and the Fifth Plenary Session of the 19th Central Committee of the Communist Party of China proposed to adhere to the core position of innovation in the overall situation of our country’s modernization drive, and to make science and technology self-reliance and self-improvement a strategic support for national development.
Those who govern the country well are good at making plans; those who decide the winner are good at making arrangements.
On January 11, 2021, the General Secretary of the Supreme Leader emphasized at the opening ceremony of the special seminar on learning and implementing the spirit of the Fifth Plenary Session of the 19th Central Committee of the Communist Party of China: "Entering the new development stage has clarified the historical orientation of our country’s development, implementing the new development concept has clarified the guiding principles of our country’s modernization construction, and building a new development pattern has clarified the path choice of our country’s economic modernization."
On March 1, 2021, the General Secretary of the Supreme Leader pointed out at the opening ceremony of the training class for young and middle-aged cadres at the Central Party School (National School of Administration): "To start a new journey of building a modern socialist country in an all-round way, based on the new stage of development, implementing new development concepts, and building a new development pattern, the risks and tests we will face will not be less than in the past."
Under the strong leadership of the Party Central Committee with the Supreme Leader as the core, and under the scientific guidance of the Supreme Leader’s Thought on Socialism with Chinese Characteristics for a New Era, we will coordinate the overall domestic and international situation, promote the "Five in One" overall layout, and coordinate the "Four Comprehensive" strategic layout. Based on the new development stage, we will implement the new development concept in a complete, accurate and comprehensive manner, and accelerate the construction of a new development pattern. We are working hard to achieve higher-quality, more efficient, fairer, more sustainable and safer development.
"Let everyone live a better life, we can’t be satisfied with the current achievements, there is still a long way to go"
In Suide County, Yulin City, Shaanxi Province, in the exhibition hall of the former site of the Suide Prefectural Committee of the Communist Party of China in Jiuzhen Temple at the foot of Shuji Mountain, there are two lines that are very eye-catching: "Stand on the side of the most working people" "Sit on the side of the ordinary people with your buttocks end to end."
On September 14, 2021, the General Secretary of the Supreme Leader came here to carefully inspect the layout of the old site and some of the restoration scenes, and visit the relevant special exhibitions. "End-to-end, this is Guanzhong dialect, steady and upright." The General Secretary said that the Communist Party of China led the people to achieve revolutionary victory, which won the hearts and minds of the people, and it was hundreds of millions of people who firmly chose to stand on our side.
"We must always have a heart-to-heart with the people, share weal and woe with the people, and work in unity with the people," said Shi Guangyin, a deputy to the National People’s Congress and party branch secretary of Shilisha Village, Dingbian Town, Dingbian County, Yulin City, Shaanxi Province. "We have established a peasant sand control company to closely integrate sand control and prosperity, so that the common people can become an important force and beneficiary group in the cause of sand control."
Governing the country is constant, and benefiting the people is the foundation.
"The people’s yearning for a better life is our goal," the Supreme Leader’s General Secretary said on November 15, 2012, when he met with Chinese and foreign reporters at the 18th Politburo Standing Committee of the CPC Central Committee.
China’s development achievements can be attributed to the fact that the lives of hundreds of millions of Chinese people are improving day by day.
Since the 18th National Congress of the Communist Party of China, the Party Central Committee with supreme leaders and comrades as the core has put forward the people-centered development ideology, adhered to everything for the people, everything depends on the people, always put the people in the highest position in the heart, The people’s yearning for a better life as the goal of struggle, promote reform and development achievements to benefit all the people more fairly, promote common prosperity to achieve more obvious substantive progress, and unite more than 1.40 billion Chinese people into a great force to promote the great rejuvenation of the Chinese nation.
"The people are the country. The Communist Party fights the country and protects the country. It guards the hearts of the people and allows the people to live a good life. The history of our party’s century-old struggle is the history of seeking happiness for the people." The general secretary’s affectionate words are full of the sincere feelings of the people’s leaders for the people.
The people-centered development concept is not an abstract or profound concept. It cannot be just a verbal or ideological concept, but must be reflected in all aspects of economic and social development.
Promote winter clean heating in the northern region, promote garbage classification, promote the treatment and resource utilization of livestock and poultry breeding waste, improve the service quality of nursing homes, standardize the housing rental market and curb real estate bubbles, strengthen food safety supervision… At the end of 2016, the "small things" and "side matters" related to people’s livelihood became the topic of the 14th meeting of the Central Financial and Economic Leading Group. "The six issues such as promoting winter clean heating in the northern region are all major events, related to the lives of the broad masses of the people, and are major livelihood projects and people’s hearts projects." The General Secretary of the Supreme Leader emphasized.
Adhere to the people as the center, the value base color of modernization is thicker and brighter.
"We promote economic and social development, in the final analysis, in order to continuously meet the people’s needs for a better life." During the 2020 National Two Sessions, the General Secretary of the Supreme Leader pointed out when participating in the deliberation of the Inner Mongolia delegation that we must always keep the people’s lives and work in peace and contentment, safety and safety in mind, and solve the practical problems of employment, education, social security, medical care, housing, pension, food safety, social security and other issues that the masses care about with heart and soul, and implement them one by one, year after year, so that the masses can see changes and get benefits.
In the process of COVID-19 epidemic prevention and control, the Party and the state have treated patients at all costs, demonstrating the great importance they attach to people’s life safety and health with practical actions. After the course of the war on the epidemic, the concept of people first took root.
Only by developing for the people can development be meaningful; only by relying on the people can development gain momentum.
"In just a few decades, we have completed the process of industrialization that developed countries have gone through for hundreds of years. In the hands of the Chinese people, the impossible has become possible. We are extremely proud and proud of the Chinese people who have created miracles on earth!" On December 18, 2018, the General Secretary of the Supreme Leader pointed out at the celebration of the 40th anniversary of reform and opening up.
On February 25, 2021, the General Secretary of the Supreme Leader emphasized at the National Poverty Reduction Summary and Commendation Conference: "As long as we always insist on serving and relying on the people, respect the main body status and pioneering spirit of the people, and fully stimulate the wisdom and strength hidden in the people, we will be able to continuously create more impressive miracles on earth!"
Under the guidance of the concept of targeted poverty alleviation, the appearance of Shibadong Village has taken on a new look. Practice has proved that by widely mobilizing the masses, organizing the masses, rallying the masses, and bringing together the wisdom and strength of the masses, we can take the initiative and fight the initiative.
Since the 18th National Congress of the Communist Party of China, the General Secretary of the Supreme Leader has repeatedly conducted in-depth investigation and research at the grassroots level, braved the wind and snow, braved the sweltering heat, stepped on the mud, walked all the way, looked all the way, thought all the way, and guided all the way.
The worries of the people, I will remember; the expectations of the people, I will do.
"Through successive efforts from generation to generation, people who used to be poor can now have a full stomach, wear warm clothes, go to school, have housing, and have medical insurance. Comprehensive well-off and getting rid of poverty is our party’s account to the people and our contribution to the world," the chairperson of the Supreme Leader said in his New Year’s message in 2022.
"Let everyone live a better life, we can’t be satisfied with the achievements in front of us, there is still a long way to go." Only by working hard and doing hard can we live up to history, the times, and the people.
Building a modern socialist country and realizing the great rejuvenation of the Chinese nation is a relay race. In the past 100 years, the Communist Party of China has handed over an excellent answer to the people and history. Now, the Communist Party of China has united and led the Chinese people to embark on a new road to achieve the second centenary goal.
With the common people in our hearts, the truth in our hands, and the right path in the world, we are full of confidence and strength. We firmly believe that the Communist Party of China and the Chinese people, who have won great victories and glory in the past 100 years, will surely win even greater victories and glory in the new era and new journey!
(Our reporters Shao Yuzi and Zhang Danhua participated in the writing)
People’s Daily (February 28, 2022, Edition 01)